At my workplace we are heavily using GitLab CI pipelines to orchestrate infrastructure as code on AWS, so we were looking for a lightweight solution to run simple GitLab pipelines on AWS.
This article will give deep insights into the proof of concept workflow of making the first serverless GitLab runner work, as well as some general experience of trying out Lambda Layers for the first time. You can find the entire code to this experiment here: https://gitlab.com/msvechla/gitlab-lambda-runner
To reduce the blast-radius inside AWS, we are isolating data and their workloads in different AWS accounts. As using IAM users with static API credentials is an anti-pattern (static credentials can leak or accidentally get committed to a repository), a different solution is needed to authorize pipeline runs. Inside the pipeline we mainly use terraform and terragrunt to setup our infrastructure. Internally, both tools use the AWS SDK for go to authenticate and authorize to AWS. This gives us multiple options to specify credentials, e.g. via environment variables, a shared credentials file or an IAM role for Amazon EC2.
When looking at existing open-source projects that deploy gitlab-runner on AWS, I stumbled upon cattle-ops/terraform-aws-gitlab-runner. This is an awesome terraform module to run gitlab-runner on EC2 spot instances. However, this originally did not support “native” IAM authentication of builds, as the module is using gitlab runner with the docker+machine executor under the hood. After creating a pull request that enables the configuration of an “runners_iam_instance_profile”, we can now use this “hack” to inject IAM credentials of the EC2 instance-profile in the metadata service as environment variables to the runner:
CRED=\\$(curl http://169.254.169.254:80/latest/meta-data/iam/security-credentials/my-iam-instance-proifile/);export AWS\_SECRET\_ACCESS\_KEY=\\\`echo \\$CRED |jq -r .SecretAccessKey\\\`;export AWS\_ACCESS\_KEY\_ID=\\\`echo \\$CRED |jq -r .AccessKeyId\\\`;export AWS\_SESSION\_TOKEN=\\\`echo \\$CRED |jq -r .Token\\\`
While this solution works and is perfect for running heavy application builds cost-efficient on EC2 spot instances, it has a lot of overhead. This solution needs at least two EC2 instances and docker to be able to perform builds, which is a lot of components to manage in each of our AWS accounts, just for running terraform. This is what sparked the idea of running builds completely serverless on lambda.
A proof of concept
While there are some obvious hard limitations, like the lambda execution timeout of 15 minutes, it still made sense to give it a try, as the idea of running builds on lambda in theory looked much more lean than managing multiple EC2 instances in all our accounts. Also a quick google search revealed that running GitLab builds on lambda apparently had not been done yet, so this seemed like an interesting proof of concept.
So what exactly did we want to evaluate:
- GitLab builds can be executed on lambda
- GitLab executor can inherit IAM permissions based on assigned role
- additional binaries and its dependencies can be executed during the build (e.g. terraform)
The idea was then to finally evaluate the solution by creating a simple s3 bucket with terraform from within a pipeline, that was executed on lambda.
As the boundaries for the experiment were set, it was now time to figure out a way to make this work. Looking at the existing GitLab runner executors, a lambda based executor did of course not exist yet. There was however a shell executor, which looked like it could be re-purposed to run builds inside a serverless function.
The Shell executor is a simple executor that allows you to execute builds locally to the machine that the Runner is installed.
In our case this “machine” would simply be our lambda function. Going over some more gitlab-runner documentation, the run-single command could then be used to execute a single build and exit. Additionally this command does not need a configuration file, as all options can be specified via parameters — perfect for our lambda function.
While in theory this should work, we still needed a solution for actually running all of this from within a lambda function. AWS recently released Lambda Layers, which allows us to share “libraries, a custom runtime, or other dependencies” with multiple Lambda functions. This was the last missing piece to the puzzle. The rough concept was now to trigger the GitLab runner in “run-single” mode and shell executor from a simple golang lambda function. This GitLab runner would then execute assigned jobs as usual, while our dependencies like gitlab-runner itself, or a terraform binary would be provided by Lambda Layers.
Building the Lambda Layers
Getting started with Lambda Layers is a simple as uploading a zip file with the content you want to share with your functions. The content will then be available in the Lambda execution context within the /opt/ directory. After uploading the gitlab-runner binary to a Lambda Layer and writing a simple golang Lambda function to execute it with the necessary parameters, I experienced the first minor success: When invoking the Lambda function, the builds that were tagged with the Lambda runner, started to execute!
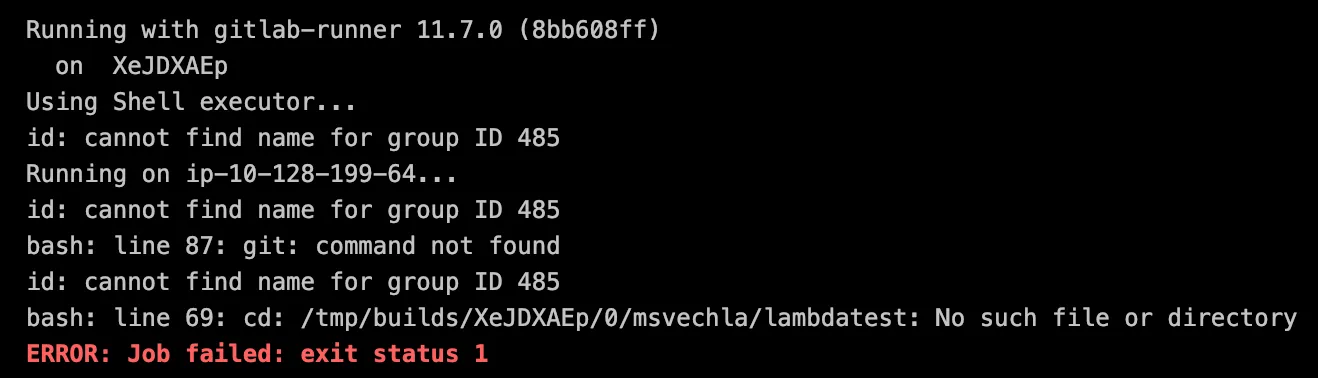
first contact
While this showed that the connection was working, the initial pre-build step of checking out the git repository was failing. Also there are a lot of confusing “id” outputs on the screen, but we will get to that later. Apparently the Lambda runtime does not come with git pre-installed, which of course makes sense. As providing GitLab runner to the function with Lambda Layers worked flawlessly, I attempted to do the same with the git binary. According to the Lambda docs, the runtime is based on the Amazon Linux AMI, so getting a compatible binary was straight forward. Next try.
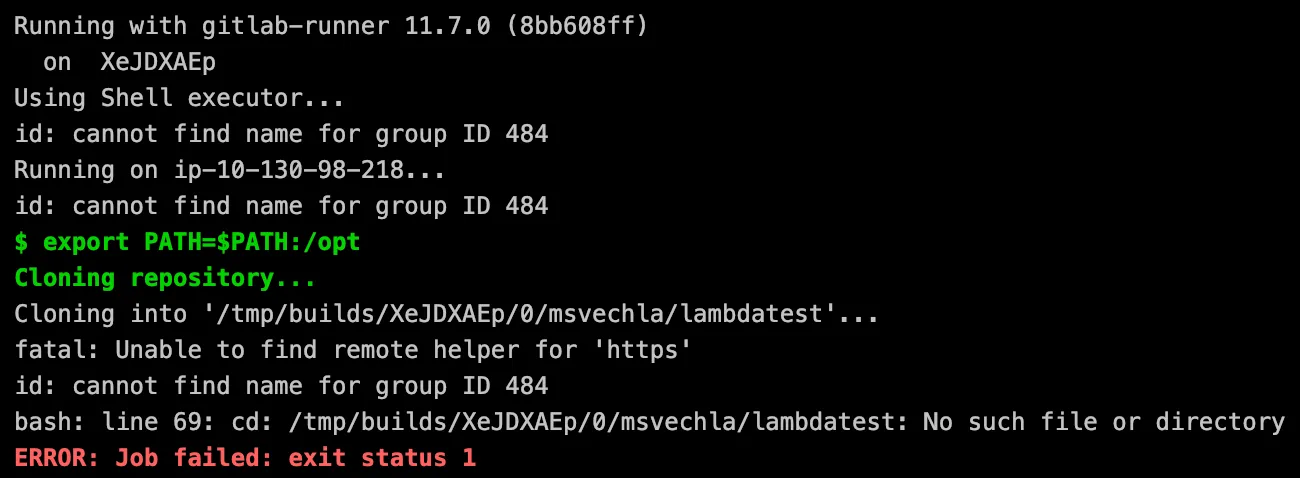
next try
While the git binary itself started cloning the repository, it looked like some dependencies were missing. After a lot of debugging, I noticed a missing “git-core” binary. During the debug session I stumbled upon the aws-lambda-container-image-converter, aka “img2lambda”. This looked like an awesome tool to build custom lambda layers based on Dockerfiles. After giving it a try and adding the missing git-core binary to the Lambda Layer, the error message was gone, but the content was still not available on the filesystem.
I realized quickly, that copying over one missing dependency after another would take forever, so I needed a different approach. This is when I found git-lambda-layer, a ready to use lambda layer with git installed. I highly recommend looking at their Dockerfile, as it gives great insight to how layers with multiple dependencies can be built. Switching to this layer worked wonders and I finy got the first successful build.
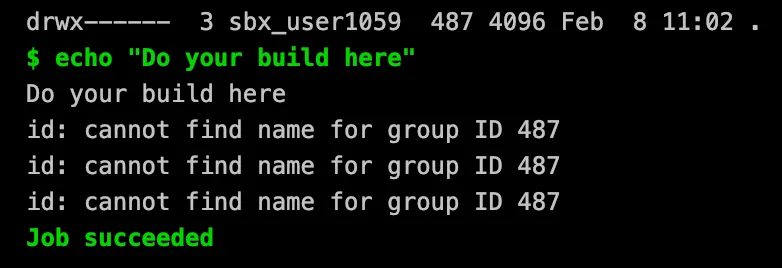
echo from the other side
Running a terraform job on Lambda
As the basics were now finally working, the last step was to actually run a terraform job to create an s3 bucket in one of our AWS accounts. Img2lambda came in very handy here again, so adding the terraform binary was straight forward. I also added a simple main.tf file to create the bucket, assigned an IAM role with full s3 access to the lambda function and voila, mission accomplished:
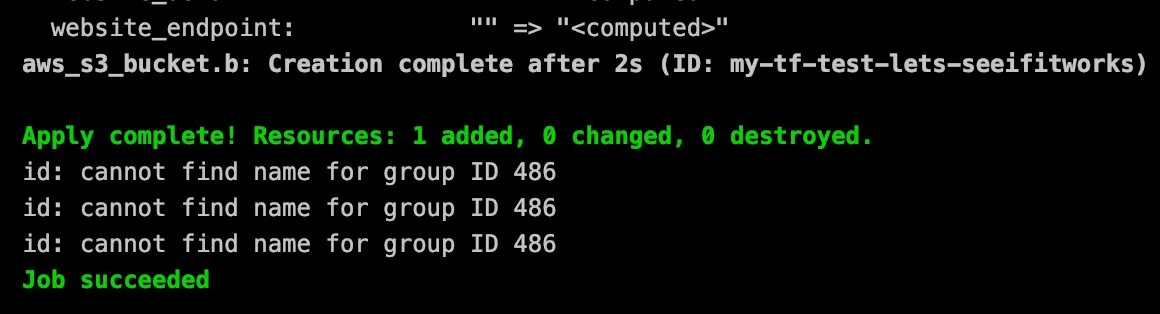
first s3 bucket created
Evaluation and Further Work
At the end this proof of concept was a full success, as all criteria that have been defined upfront, were evaluated successfully. However there are of course still issues that need to be solved. The main problem is triggering the lambda function when a build job requires it. During the proof of concept I manually triggered the lambda function after a build job started. This could be solved by regularly triggering the lambda function via a CloudWatch schedule, however it would not be very efficient. Ideally the lambda should be triggered from the GitLab server directly. Another solution would be to implement a GitLab runner “lambda” executor, that listens for incoming jobs and then triggers the lambda function. Further possibilities can be evaluated in a future proof of concept.
Also there is still the error about the “id” error messages during pipeline execution. Running the “id” command manually shows that there is indeed no name for the lambda users group:
uid=488(sbx\_user1059) gid=487 groups=487
I traced down the id calls to the /etc/profile inside the Lambda function, which of course gets triggered by the shell executor, but I did not find a solution here yet. Feel free to leave a comment if you have an idea on how to solve this.
Try it out yourself
As a lot of people are excited to run builds on lambda, I open-sourced all necessary files, as well as a deployment script to get you started. Check it out here: https://gitlab.com/msvechla/gitlab-lambda-runner
While it does not make sense to run most traditional build-jobs inside a Lambda function, there are use-cases where it can make sense. If you are interested in working on this, feel free to open a PR or let me know what you think about this on twitter.