Photo by Patryk Grądys on Unsplash
11:00 AM, 02/22/19: Press Conference
Dieter Zetsche and Harald Krueger enter the stage to announce the new mobility joint venture. At the same time, a few kilometers away in Berlin, the excitement inside the war room grows.
This room filled with around 30 people with various backgrounds, from communications over marketing to engineering and management, coordinated and executed the go-live of this new joint venture. While there were a lot of things going on, like releasing the new co-branding on all platforms or enabling the feature toggle to display car2go and drivenow vehicles side-by-side in the apps, this article solely focuses on the launch of the new website.
The start of the press conference did not only share all the big news with the public, it also signaled green light for setting the page live. As until now the website had been protected via a web application firewall and basic-auth, these protective measures had to be removed, so customers all over the world would be able to access the site. As the entire infrastructure for the site is defined in code via terraform / terragrunt, the toggle to disable these protections had already been prepared upfront:
allowed_ips = [] // an empty array disassociates the WAF from the CloudFront distribution
> terragrunt apply-all
Executing this simple command synchronized our cloud setup with the infrastructure code definitions in our git repository. A couple of minutes later, the CloudFront distribution had been updated on all edge locations.
The site was now live.
While from a technical perspective this launch was mostly uneventful, this is exactly how a well-planned releases should be: without surprises. This is of-course only possible with a solid architecture, early monitoring, planning and rehearsing. So let’s take a look under the hood.
A Flexible Architecture with Global Reach and Low-Latency
As we had a separate team working on the web-application and its content, we needed a clean and widely understood interface to deploy this application. With every web-application there are multiple reviews with different stake holders, as well as lots of different versions with various changes that need to be evaluated in parallel. With these requirements in mind, we decided on Kubernetes as our application platform of choice.
Kubernetes abstracts away the infrastructure and provides a common and widely accepted interface for application deployments.
This made it fairly simple for multiple teams to work on the final solution, as the application deployment model did not have to be re-invented over and over again. Also the “namespace” concept of Kubernetes is a good way of isolating different preview deployments of the final application, as well as accessing and evaluating them in parallel.
For the launch we also had to ensure a good performance and low-latency for customers around the world, as well as potential DDoS protection and IP filtering for allowing a small audience to test the final website deployment upfront. Additionally the web-application needed access to a mysql database for storing dynamic content created by our content editors.
As some of our other applications were already running on Amazon Web Services, this was an easy decision to make. Especially as all requirements were covered with the Elastic Kubernetes Service (EKS), Aurora MySQL, CloudFront and Web Application Firewall (WAF) / AWS Shield, which resulted in the following simplified architecture:
Visitors would access the site via the DNS entry for your-now.com, which points to a CloudFront distribution. The CloudFront origin has a WAF and Lambda@Edge function associated, to restrict access to the site before go-live. The origin of the CloudFront Distribution consists of an Application Loadbalancer (ALB), which targets the Autoscaling Groups (ASGs) of the EKS worker nodes. These can contain a mixture of on-demand and spot-instances, to keep a stable baseline with flexible scaling, while keeping the costs at a minimum. Cluster Autoscaler then dynamically adjusts the desired instances inside these ASGs based on the resource demands inside the clusters. The application itself is deployed as a a “Deployment” artefact, with a flexible number of replicas.
The deployment is exposed to the ALB via a Kubernetes Service of type “NodePort”. While we could use a Service of type “LoadBalancer” to create an ELB pointing to our deployment automatically, this would make it difficult to keep all components under version control in our infrastructure as code (IAC) repository. As AWS will dynamically provision an ELB with a random DNS name, there would be no simple way of referencing it in our CloudFront distribution as an origin. By defining the ALB upfront in code and pointing it to the NodePort service, the origin endpoint will be stable, even when the deployment or service definitions inside Kubernetes are adjusted.
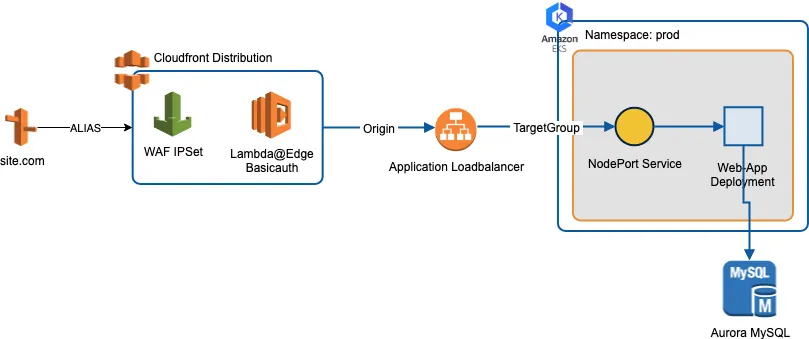
AWS Architecture Diagram
While this architecture looked good on paper, it still had to be evaluated for production use-cases.
Deploy and Monitor as Early as Possible
One of the biggest takeaways from this successful launch, was our approach to deploy to the final environment as soon and often as possible, while monitoring it from the beginning.
Continuous monitoring of all infrastructure and application components already during the development process is key to a successful launch.
As we had the possibility to allow a small amount of people to evaluate the final site upfront via IP Whitelisting and Basic Authentication, we could use similar mechanisms to allow access to our monitoring tools.
New Relic has awesome “Synthetics” browser checks, which try to load your webpage from different virtual browser instances around the globe. Their Public Minion IPs are published as JSON objects daily, which allows us to allow-list the specific monitors automatically. Additionally, New Relic sets custom X-Abuse headers with every request, that can be used to identify and allow-list their monitoring systems. These synthetics checks are a good mechanism to tweak the CloudFront configuration for optimized caching, as we get access to the details of every browser check executed. This enables us to evaluate the Hit or Miss from CloudFront response headers and make adjustments to the configuration as necessary.
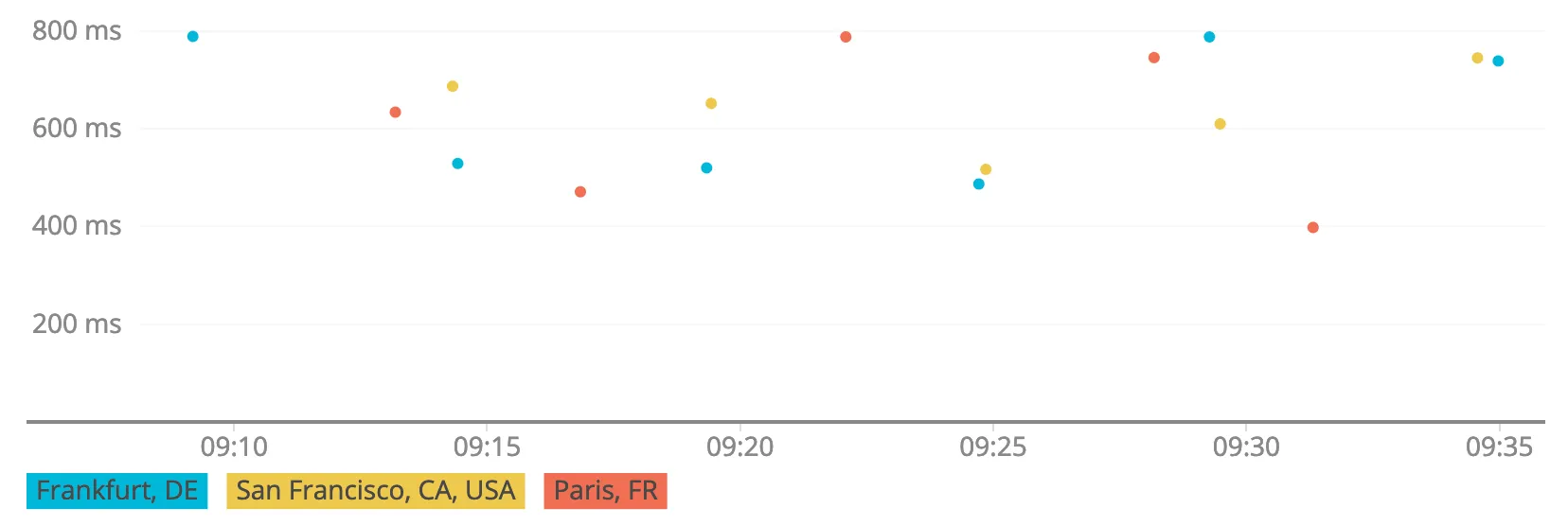
Exemplary Synthetics Browser Checks
For performance and availability monitoring of the remaining components we use DataDog. Their AWS Integration is perfect for serverless monitoring of key infrastructure components. As DataDog can get access to our monitoring data via AWS Identity Access Management (IAM) directly, there is no need to deploy and manage any components ourselves. This is a good way for monitoring the Aurora instances and to get basic performance metrics of our CloudFront distribution. However, monitoring the Kubernetes cluster with their Kubernetes Integration, is only possible by deploying a monitoring agent to EKS. Using the official helm chart, this process is straightforward. Additionally, we can make use of the autodiscovery feature, to dynamically add checks to our cluster. This can be used to check the connectivity to the application via the CloudFront distribution, the ALB or the NodePort service directly, to easily identify faulty components in the chain.
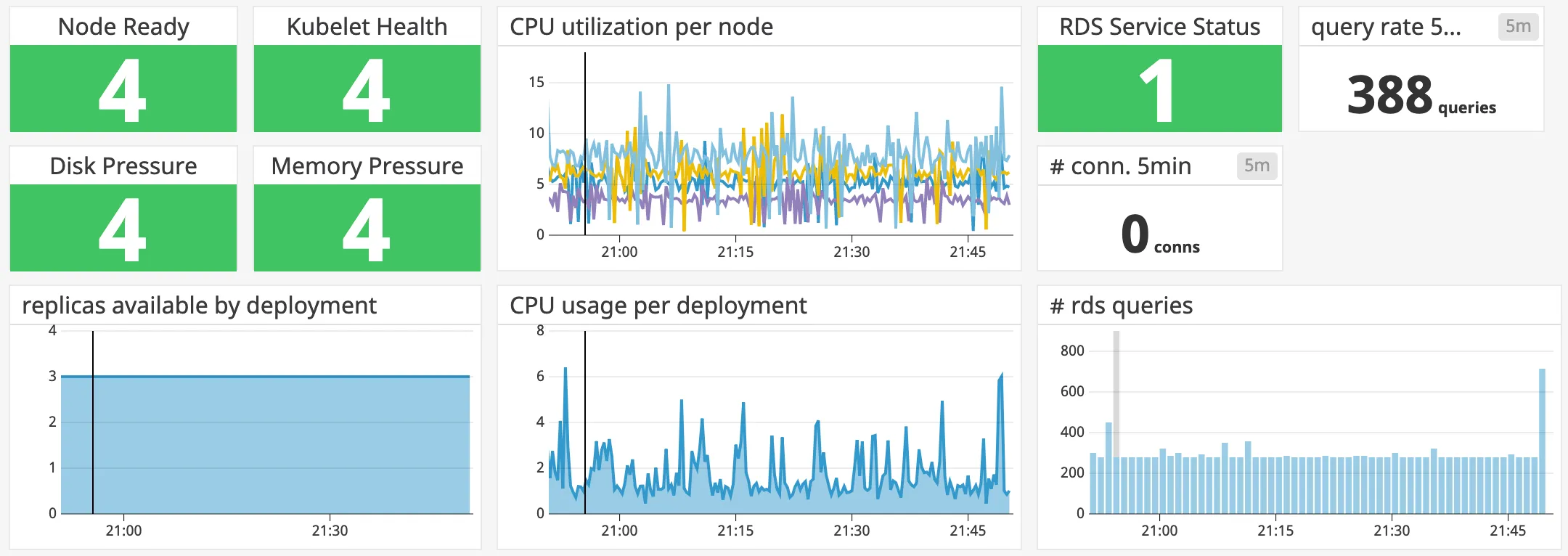
Exemplary Datadog Dashboard
By enabling these monitoring checks from the beginning, we always had a complete and clear picture of the infrastructure and application health throughout the development process, which was key to a successful launch.
Key Elements to a Successful Launch
The previous paragraphs already explained the importance of a good architecture and early monitoring to enable a smooth go-live, but there are a lot more elements to consider.
Document your go-live procedures. Having all necessary steps as a markdown file in your repository facilitates thinking about all important details upfront. It also ensures others can take over the required steps if necessary.
While we take infrastructure as code very seriously, there can be use-cases where manual steps during a go-live are the better approach. As long as the IAC repository can get synchronized with the actual state in the cloud easily after go-live, this can be a valid approach for small changes.
Rehearse! We tested the go-live on staging environments upfront, so there will be no surprises during the actual release. Even then there can be minor issues during launch. However when applied correctly, major issues should already surface during rehearsal.
And last but not least: Teamwork. Having a second set of eyes on everything during a mission-critical launch, will create a more pleasant atmosphere than being in the war room on your own. Also there will be more people to celebrate a successful launch together 🎉